INTRODUCTION
Obstructive sleep apnea (OSA) is closely related to important medical conditions such as hypertension, cardiovascular diseases, neurovascular diseases, and metabolic syndromes [1]. In addition, the prevalence of OSA reaches approximately 26% in middle-aged to older adults [2] and is increasing with the rate of obesity in the general population. However, OSA is frequently underrecognized and underdiagnosed, possibly because of the limited accessibility of diagnostic tests due to high costs and insufficient test facilities for sleep studies.
The gold standard examination is attended, in-laboratory, full-night polysomnography with multichannel monitoring. Although it provides an exact set of sleep data including apnea hypopnea index (AHI), many subjects at risk of OSA cannot afford polysomnography. Thus, various portable or at-home sleep test devices have been developed and are currently in use. However, current tests with portable devices also incur high expenses when performed repeatedly [3].
Recently, multiple smartphone applications have been developed to prescreen snoring or OSA [4,5]. They can be easily downloaded and used in open application online markets. During sleep, various signals are continuously produced by the body that may be used for prediction of OSA severity; these signals include respiratory sounds, such as silent or loud breathing sounds, regular or irregular breathing sounds, snoring, gasping, and cessation of breathing sound. Respiratory sounds during sleep can be easily recorded by using microphones embedded in most currently available smartphones. However, their performance and accuracy have rarely been compared and tested through simultaneous studies with polysomnography.
In the present study, we extracted a large volume of audio features from sleep breathing sounds recorded during full-night polysomnography, in which respiratory sound signals were perfectly synchronized with other body signals in the polysomnographic data set. The current study was performed to develop algorithms for prescreening of OSA with a large set of audio features and evaluate their performances in comparison with the results based on polysomnography.
MATERIALS AND METHODS
Study participants and polysomnography
Patients with habitual snoring, with or without witnessed apnea, who underwent attended, in-laboratory, full-night polysomnography at a sleep center of a tertiary hospital between October 2013 and March 2014, were included in this study. Patients were excluded if they had central sleep apnea, neurological disorders, neuromuscular disease, heart failure, or any other critical medical condition. Polysomnography (Embla N 7000, Reykjavik, Iceland) included electroencephalography, electrooculography, chin and limb electromyography, electrocardiography, nasal pressure transducer, thermistor, chest and abdomen respiratory inductance plethysmography, and pulse oximetry. OSA and hypopnea were defined as previously described [6]: apnea was defined as cessation of airflow for at least 10 seconds, while hypopnea was defined as a >50% decrease in airflow for at least 10 seconds or a moderate reduction in airflow for at least 10 seconds associated with arousals or oxygen desaturation (<4%) [7]. AHI was defined as the total number of apneas and hypopneas per sleep hour. Written informed consent was obtained before enrollment and the study protocol was approved by the Institutional Review Board of Seoul National University Bundang Hospital (IRB No. B-1404/248-109).
Collection and preprocessing of sleep breathing sounds
For all patients, audio recordings were performed throughout the night of polysomnography by using an air-conduction microphone (SURP-102; Yianda Electronics, Shenzhen, China) linked to a video recorder, which was placed 1.7 m above the patient’s bed, near the ceiling (Fig. 1). Respiratory sounds recorded throughout the sleep time were used for analyses. Analyses were performed by using audio data from all sleep stages comprising stage N1 sleep, stage N2 sleep, stage N3 sleep, rapid eye movement sleep, and waking, from sleep onset to sleep offset. Audio data from each patient were converted into a wave format file with an 8-kHz sampling frequency by using FFmpeg, which is a free software for handling multimedia data [8]. Noise reduction was conducted for preprocessing with a spectral subtraction method [8].
Extraction of audio features
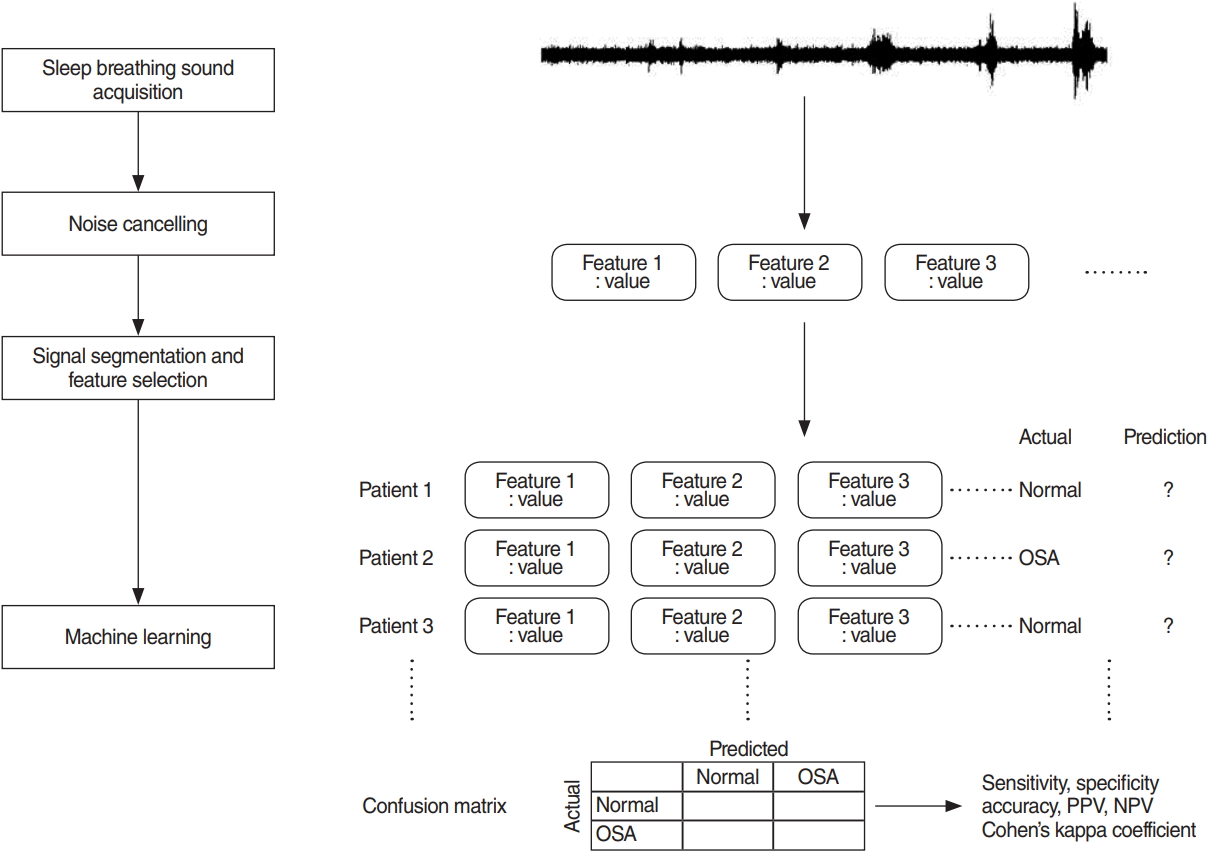
To extract audio features that describe the characteristics of respiratory sounds and can be used for prediction of OSA, full-length, de-noised audio data of each patient were segmented into 5-s window signals and a large set of audio features was extracted from those 5-s window signals by using jAudio, a Java-based audio feature extraction software. The audio feature extraction framework is summarized in Fig. 2.
Prediction of OSA
Prediction of OSA, based on breathing sounds during sleep time, was performed with a simple logistic regression model. To establish and validate prediction models, or classifiers, 10-fold cross-validation was used. Enrolled patients were randomly divided into 10 equal-sized subgroups. Of the 10 subgroups, a single subgroup was retained for validation of the prediction model; the remaining nine subgroups were used for training. The cross-validation process was then repeated 10 times (10 folds), with each of the 10 subgroups used once for validation. This gives 10 evaluation results, which are averaged. Then learning algorithm was then invoked a final (11th) time on the entire dataset to obtain the final model [9]. Model performance measures, such as accuracy, sensitivity, specificity, positive predictive value (PPV, precision), negative predictive value (NPV), and area under the curve (AUC) of the receiver operating characteristic, were computed for each fold. Binary classifications were conducted for three different threshold criteria at AHI of 5, 15, or 30; prediction models (classifiers) were separately established for each threshold. Machine learning was performed with a free software, Weka [9]. Other statistical analyses were performed by using IBM SPSS ver. 22.0 (IBM Corp., Armonk, NY, USA). Results are presented as mean±standard deviation.
RESULTS
General characteristics and polysomnographic findings
A total of 116 subjects (78 men and 38 women) with a mean age of 50.4±16.7 years were included in the present study. Their mean body mass index was 25.5±3.9 kg/m2, and the mean AHI was 23.0±24.0/hr. The numbers of subjects with AHI <5, 5≤ AHI <15, 15≤ AHI <30, and AHI ≥30 were 28, 28, 30, and 30, respectively. Their characteristics, according to OSA severity, are summarized in Table 1. The mean total sleep time between sleep onset and offset was 369.7±104.8 minutes.
Characteristics of sound-associated features
The mean number of 5-s windows from the respiratory sounds recorded during total sleep time was 4,436.8±1,258.4 per patient. A total of 508 audio features were extracted from those windows using the jAudio software. The representative features were beat histogram, area method of moments, Mel frequency cepstral coefficient (MFCC), linear predictive coding, area method of moments of constant Q-based MFCCs, area method of moments of log of constant Q transform, area method of moments of MFCCs, and method of moments (Table 2).
Performance of binary classifiers for OSA
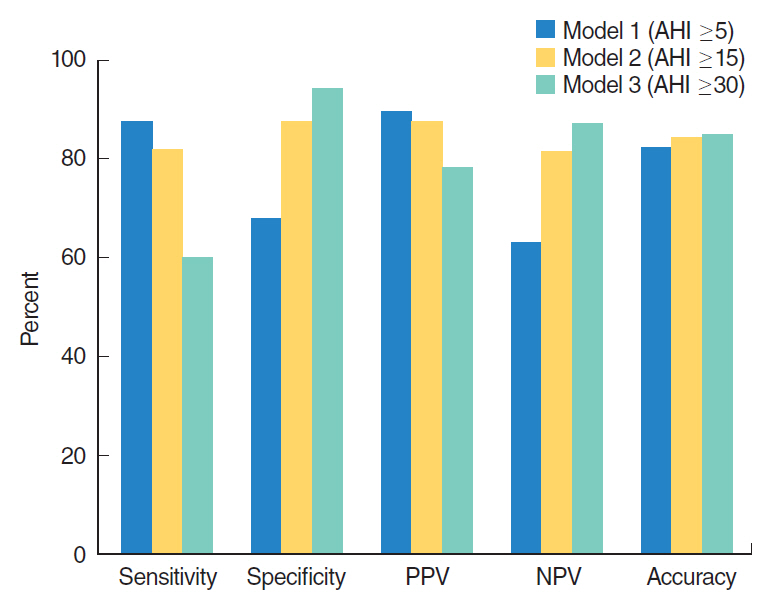
When the AHI threshold for binary classification was defined as 5, 15, and 30, the numbers of subjects whose OSA severity was accurately predicted was 96 (82.7%; Cohen’s kappa coefficient (κ)=0.54, 95% confidence interval [CI], 0.36 to 0.72), 98 (84.4%; κ=0.69; 95% CI, 0.51 to 0.87), and 99 (85.3%; κ=0.59; 95% CI, 0.41 to 0.77), respectively, out of 116 subjects.
When the AHI threshold criterion was 5, 88 subjects had mild to severe OSA with AHI ≥5. The sensitivity and specificity of the prediction model (classifier) at AHI of 5 were 87.5% (95% CI, 78.3% to 93.3%) and 67.8% (95% CI, 47.6% to 83.4%), respectively. The PPV (precision) and NPV were 89.5% (95% CI, 80.6% to 94.8%) and 63.3% (95% CI, 46.9% to 79.5%), respectively. When the AHI threshold was 15, 60 subjects had moderate to severe OSA with AHI ≥15, based on polysomnography. The sensitivity and specificity of the binary classifier at AHI of 15 were 81.6% (95% CI, 69.1% to 90.1%) and 87.5% (95% CI, 75.3% to 94.4%), respectively. The PPV and NPV were 87.5% (95% CI, 75.3% to 94.4%) and 81.6% (95% CI, 69.1% to 90.1%), respectively. When the AHI threshold was 30, 30 patients had polysomnographic severe OSA with AHI ≥30. The sensitivity and specificity of the binary classifier at AHI of 30 was 60% (95% CI, 40.7% to 76.8%) and 94.1% (95% CI, 86.3% to 97.8%), respectively. The PPV and NPV were 78.2% (95% CI, 55.8% to 91.7%) and 87% (95% CI, 78.2% to 92.9%), respectively. Average AUCs were 0.83, 0.901, and 0.91, when the prediction models of binary classifications were tested for different cut-off values at AHI of 5, 15, and 30, respectively. The results are summarized in Fig. 3.
DISCUSSION
The purpose of this study was to analyze all respiratory sounds occurring between sleep onset and offset based on polysomnography and then predict OSA by using respiratory sounds from patients during sleep time. More than 500 variables, or features, that were extracted from the breathing sounds were used to develop a classifier (i.e., an OSA-predicting machine learning algorithm).
We evaluated binary classifiers that were trained to classify patients into two groups. The binary classifier for AHI of 5 had the lowest specificity, while the classifier for AHI of 30 had the lowest sensitivity and lowest precision (PPV); accuracies of the three classifiers were similar. Cohen’s kappa coefficient, which measures interrater agreement for categorical values, was highest when the cutoff value of AHI was set at 15. Therefore, the best performance of the OSA prediction algorithm with recorded respiratory sounds during sleeping time was observed when AHI of 15 was the classification cutoff.
Thus far, few studies have been performed with sounds that were generated during sleep, especially involving machine learning techniques; most studies have been conducted with a small number of patients [10-13]. Previous studies mainly focused on analyzing the characteristics of snoring, or distinguishing snoring from non-snoring sounds. One study reported that the classification performance of human visual scorers and a machine learning algorithm was similar in terms of automatically identifying snoring; this study used a support vector machine, which is a machine learning technique [14]. There have also been studies that used analysis of snoring sounds to predict the anatomical location in the upper airway where the snoring sounds were generated [15-17]. However, analyses in these studies were limited to only a short period of time, drug-induced sleep. Another study used neural network analysis to separate snoring from non-snoring segments; this study also analyzed only breathing sounds from the trachea, and was performed in very few patients (<10) [18]. Another study of the trachea respiratory sound was performed in 147 awake patients; it reported that prediction based on breathing sounds was superior to that based on anthropometric features in predicting polysomnographic AHI of ≥10 [19]. However, it differs from our study in that sounds were recorded when the patients were awake. A further study attempted to distinguish apneas from hypopneas by using audio signals. When all 2,015 apneas or hypopneas were analyzed, the accuracy was approximately 84.7%, which suggests the possibility of estimating apnea or hypopnea separately. However, considering that automatic detection of apneas and hypopneas has not been validated to estimate AHI as a measurement of OSA severity extracted by human scorers, further studies are needed for automation [20]. We have previously conducted studies to predict the severity of OSA by analyzing breathing sounds during sleep with machine and deep learning methods [8,21]. Although our previous studies used respiratory sounds during sleeping time, they were limited in that only N2 and N3 stages were included for analysis. Therefore, the present study is distinguished from our previous studies in that we tested prediction algorithm models in all sleep stages, including N1, N2, N3, rapid eye movement, and waking stages, between sleep onset and offset. Classifiers should be as simple and accurate as possible in predicting OSA. For this purpose, it is important to use the sounds of all sleep stages without any identification and/or separation of sleep stages.
The development of OSA prediction algorithms may be important in many respects. First, if predictive models are proven to have a certain level of performance, more patients will have the opportunity to prescreen their own OSA. In practice, considering the limitations of conventional polysomnography, many patients with OSA are underdiagnosed, despite its high prevalence (26% in middle-aged men) [22]. Individuals with repetitive snoring, daytime sleepiness, or poor sleep quality without definite OSA must now travel to the hospital for polysomnography. Regarding ambulatory home monitoring devices, there is a limitation (similar to polysomnography) in that symptomatic patients must first visit hospitals equipped with the appropriate devices. Second, the prediction algorithm tested in our study is an important contribution because most people currently use smartphones. Notably, smartphones have a sound recording function, which may enable prescreening of OSA [23]. Third, this type of prediction algorithm can be used for repetitive tests without economic or spatial burden. Therefore, given the night-to-night variability of OSA [24], it is useful to evaluate the average sleep state for an extended period of time, and to regularly monitor the effects of operation or intraoral devices. Fourth, this research may motivate more OSA patients to visit hospitals, thereby increasing the likelihood that they will undergo polysomnography and start treatment at the appropriate time. Since the risk of multi-organ diseases, such as cardiovascular, neurovascular, and metabolic diseases, may be reduced by early treatment of OSA, their social and economic burdens may decrease [25].
Our research also has several limitations. To be utilized in personal mobile devices, it is necessary to use the sound recorded from smartphones. While we have been able to synchronize polysomnography to determine sleep onset and offset, these may be incorrectly determined when measured at home with a smartphone. Since the algorithm that we tested was a binary classifier, we could not distinguish the degree of OSA severity in detail. Overall performance was acceptable; however, it should be further increased. There may be several reasons for this, including inter-person variability of breathing sounds during sleep. The performance of the classifier may be improved by including more patients in future analyses. In addition, it is possible to develop algorithms that can predict apnea or hypopnea, as well as the severity of OSA. This study was based on a single session of polysomnography in each patient; therefore, it is also necessary to evaluate night-to-night variability of breathing sounds during sleep. Further, sound acquisition from the microphones of commercial smartphones, placed at the bedside, which is closer to real-world usage, must be also validated.
In conclusion, our binary classifier predicted patients with AHI of ≥15 with sensitivity and specificity of >80% by using respiratory sounds during sleep. Our study has strength in that it used data recorded in synchronization with polysomnography during actual sleep time. In addition, since our prediction model included all sleep stage data between sleep onset and offset, prediction classifiers based on respiratory sounds may have high future value as prescreening algorithms for OSA that can be used in personal mobile devices. Although our study used a large volume of patient data to diagnose OSA based on respiratory sounds, further studies with additional patients are needed to improve the performance of prediction algorithms.
HIGHLIGHTS
▪ Analyses included respiratory sounds from all sleep stages, including N1, N2, N3, rapid eye movement, and waking.
▪ We analyzed quite many patient sounds simultaneously recorded with polysomnography.
▪ Our binary classifier predicted patients with apnea hypopnea index of ≥15 with sensitivity and specificity of >80% by using respiratory sounds during sleep.